


Sign up for daily news updates from CleanTechnica on email. Or follow us on Google News!
At present we’re in another wave of hysteria regarding data center energy demands, this time focused on concerns related to AI. It was all over Davos, for example. Many decarbonization folks, although not me, are deeply concerned about the electricity demands of the various large language models and generative AI systems. This all sounds very familiar to me, as does the inevitable response.
I’ll get to the two key pieces of news, one from last year and one quite recent, that are indicative that the demands won’t be nearly as severe as current claims indicate, but first, a trip down memory lane.
The dot-com boom of the late 1990s and early 2000s marked one of the earliest periods when rising energy use became a major concern. The explosive growth of internet companies led to a surge in data center construction, raising alarms about the mounting power demands and cooling requirements. In response, the industry began exploring ways to improve server efficiency and alternative cooling methods to mitigate rising energy costs. It was likely in the 1990s that I first saw terrified memes about how much energy an email took to send.
In 2006, the U.S. Environmental Protection Agency brought national attention to the issue with a landmark report to Congress. The study estimated that data centers accounted for about 1.5% of total U.S. electricity consumption and warned of continued exponential growth. This prompted widespread efforts to develop energy-efficient solutions, including server virtualization and consolidation strategies aimed at reducing overall power consumption. In 2014, data center demand was only 1.8%, so that was another example of crying wolf.
The 2010s saw the rapid expansion of cloud computing, with companies such as Amazon Web Services, Google Cloud, and Microsoft Azure building hyperscale data centers to meet growing demand. The sheer scale of these operations reignited concerns over sustainability and environmental impact. In response, major cloud providers began investing heavily in renewable energy, with commitments to power operations entirely through wind, solar, and other sustainable sources. Palpitations about the horrors of data center demand evaporated again.
A new wave of concern emerged with the rise of cryptocurrency mining, particularly Bitcoin, in the late 2010s. The energy-intensive nature of blockchain validation processes drew scrutiny, with studies indicating that the energy consumption of Bitcoin mining rivaled that of small nations. Governments, including China, imposed strict regulations or outright bans on mining operations, while the industry sought more energy-efficient algorithms and renewable-powered mining solutions. Bitcoin remains a useless energy hog with criminal and prepper devotees, but most of the rest of the big blockchain technologies pivoted to proof of stake from energy intensive proof of work, just as was occurring in 2018 when I published a lengthy report (full report available here) on blockchain and clean technologies.
The COVID-19 pandemic triggered an unprecedented surge in digital activity as millions of people shifted to remote work, online shopping, and streaming services. This sudden spike in demand placed immense pressure on data centers, raising concerns about their ability to maintain resilience while managing significant power consumption increases. In response, data center operators invested heavily in automation and hybrid cloud solutions to optimize workloads and reduce unnecessary energy usage. These strategies aimed to ensure reliable service delivery while addressing mounting environmental and operational challenges in an era of accelerated digital transformation. And they did.
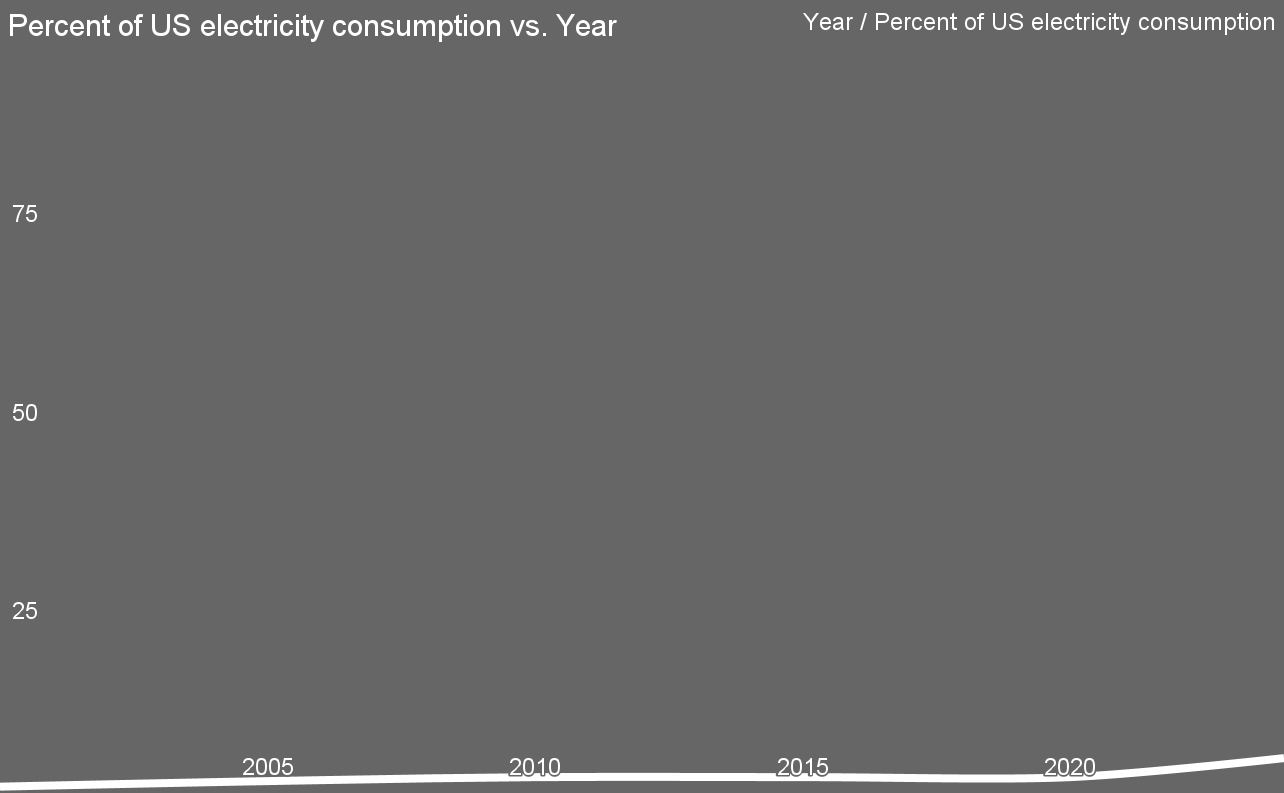
I just pulled together a data set of data center demand in the USA by year since 2000. Note how most of the concerns were crying wolf?
Think about how much of what you do flows through data centers now. Think of all your FaceTime, Zoom, and Google Meeting calls, something that existed only for rich corporations 25 years ago. Think of all the time you spend on YouTube, Instagram, or TikTok, things that didn’t exist 25 years ago. Think of all the streaming movies you watch on Amazon Prime, Netflix, or Apple TV, once again something that was non-existent 25 years ago. Think of your constant messaging with friends on innumerable platforms, something that barely existed 25 years ago. Think of your endless browsing for just the perfect rug to pull the room together that you do on home decor websites instead of in glossy magazines delivered to your door, once again an affordance that didn’t exist 25 years ago. Think of all of your internet banking and investment work, something which was just appearing 25 years ago. Think about the massively multiplayer online role-playing game (MMORPG) genre, which includes high-use titles such as World of Warcraft, Final Fantasy XIV, and The Elder Scrolls Online, none of which existed 25 years ago.
What percentage of your life is now spent online? The digital economy in the USA has risen from 3% in 2000 to well over 10% now, yet energy demands from data centers barely moved from 2005 to 2020. Data center electricity demand has bumped up with the AI efforts, with 4.4% of electricity demand in 2022 coming from data centers.
Now it’s AI’s turn to create an energy and sustainability hysteria. If you’re wondering why I, as a technologist and strategist who has been involved in specifying data centers, AI, and blockchain at various times in my career, am not hyperventilating about hyperscaling data centers, it’s in part to being aware of the history of hysteria related to this. You’ll note that putting the appropriate scale on the data center electricity demand makes it seem like less of a problem. Just to put it out there, there are concerns, but they aren’t really the ones most people are talking about.
I’ve also been involved in architecting or rearchitecting possibly into the low hundreds of technical solutions. I’m doing it again with my new firm Trace Intercept, as we leverage modern high-resolution video and image capture, large language models, and Gaussian splatting to create almost instant digital twins of existing infrastructure to enable maintenance to keep up to a changing climate. That number isn’t particularly unusual for someone who spent decades in the space in consulting and software organizations, and worked a lot in the proposal phases of projects. Keep doing something long enough, and eventually you’ve done a lot of stuff. Among other things, for three years I was Canada’s troubled project fix-it guy for one of the biggest technical consultancy, hardware, and software firms in the world, which meant I was dropped into new failing contracts every week or two for much of that time, and often the problems were that we sold the client a terribly architected proposal which needed to be refactored.
But there’s something else I’m aware of that people who haven’t spent careers in technology aren’t. There’s a basic rule in software engineering and that’s that barring some very specific requirements or deployment constraints, you optimize for performance late, if at all. You test performance of the solution as it emerges as a leading practice, but you don’t bother to optimize it unless it’s turning out to be a pig.
I was involved in remediating performance concerns on perhaps a dozen of the low hundreds of projects. I was the performance architect on a rewrite of a provincial social services system and was heavily involved in remediating performance on a major drugstore chain’s new point of sale terminals, for example. I’m struggling to remember other examples where performance was actually an issue, but I’m sure that there were a few more.
When I saw rising concerns about energy demand from large language models and generative AI, in other words, I knew that optimization would be occurring shortly and that actual energy demand requirements would end up being much lower than the hyperbolic concerns.
And so to the older news. NVIDIA unveiled its new Blackwell GPU architecture at the GTC 2024 keynote on March 18, 2024. The flagship GB200 NVL72 model offers up to a 30-fold performance increase for large language model inference tasks compared to its predecessor, the H100 Tensor Core GPU, while slashing energy consumption by as much as 25 times. The company’s GB200 Grace Blackwell Superchip boasts a 25-fold improvement in energy efficiency over the previous Hopper generation in AI inference applications. NVIDIA is already shipping to data centers and resolving the usual early run glitches and plans to release its first consumer GPUs based on the Blackwell architecture, the GeForce RTX 5090 and RTX 5080, on January 30, 2025. Expect garage-based startups to buy their own little data centers for their own AI training, delivering better models and having lower energy bills.
Note that this is just the processors. Moving data around between them is also energy intensive, so the actual results in data centers won’t be 4% of the energy requirements, but it won’t be the levels considered in a lot of the projections of data center energy demand taking over the world.
But that’s hardware. There’s another rule in optimization, which is that if you have a performance problem, scale up the hardware first. Well over 90% of problems with performance in complex systems have been resolved by bigger boxes. But that’s not the only lever to pull. The history of computing is bright people finding incredibly clever ways to optimize software as well. Historically that was a requirement because the boxes weren’t big. I remember the first software program I developed for myself in Grade 11, I think. It was running on a Timex Sinclair computer, which was one of the first computers that could be bought and used at home. I wrote a Dungeons & Dragons encounter generator. (Yes, I’ve always been a nerd.) I had to break the program into five chunks that were loaded sequentially from a cassette tape because memory was so limited, about 16 kilobytes, compared to a modern iPhone, which has almost 550,000 times more. The hardware limitation went away almost immediately.
When I was solutioning putting a potential client’s entire IT infrastructure and their ‘big data’ marketing analytics solution into the Cloud due to a divestment of the firm from the parent firm a few years ago, one thing I had to keep reminding the team about was that the entire big data marketing database would run on an iPhone. The big data was 750 megabytes and at the time I think the smallest deployment our storage solution people typically considered was two petabytes, 300,000 times more than the ‘big data’ requirement, because we dealt with banks, insurance firms, and governments. Performance wasn’t remotely a concern.
However, for the drugstore point of sale solution, the cash registers were a hard limit, and the points system the chain used was absurdly complex. It should have been refactored, but instead they just made the absurd complexity our problem. In that case, we had to optimize the software, and did. We got it from 10 or 20 seconds per scan of a bottle of shampoo down to well under a second, just by making the algorithms more efficient. That was a very rare occurrence.
The reason for scaling up the hardware first is that hardware is cheap compared to coders, so you go for the cheap optimization pathway first, second, and third, and then only reluctantly get bright coders to figure out how to refactor the code to be performant.
And so to the second piece of news regarding large language models and generative AI demands, software efficiency improvements from DeepSeek, a Chinese firm. They focused on software optimization rather than relying on Western GPUs primarily due to geopolitical and economic constraints. U.S. export restrictions on advanced semiconductor technology, particularly high-performance GPUs from companies like NVIDIA, have limited China’s access to cutting-edge hardware essential for training large AI models. In response, DeepSeek turned to software-driven innovation to maximize efficiency and performance using the hardware available domestically.
we introduce DeepSeek-R1, which incorporates cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
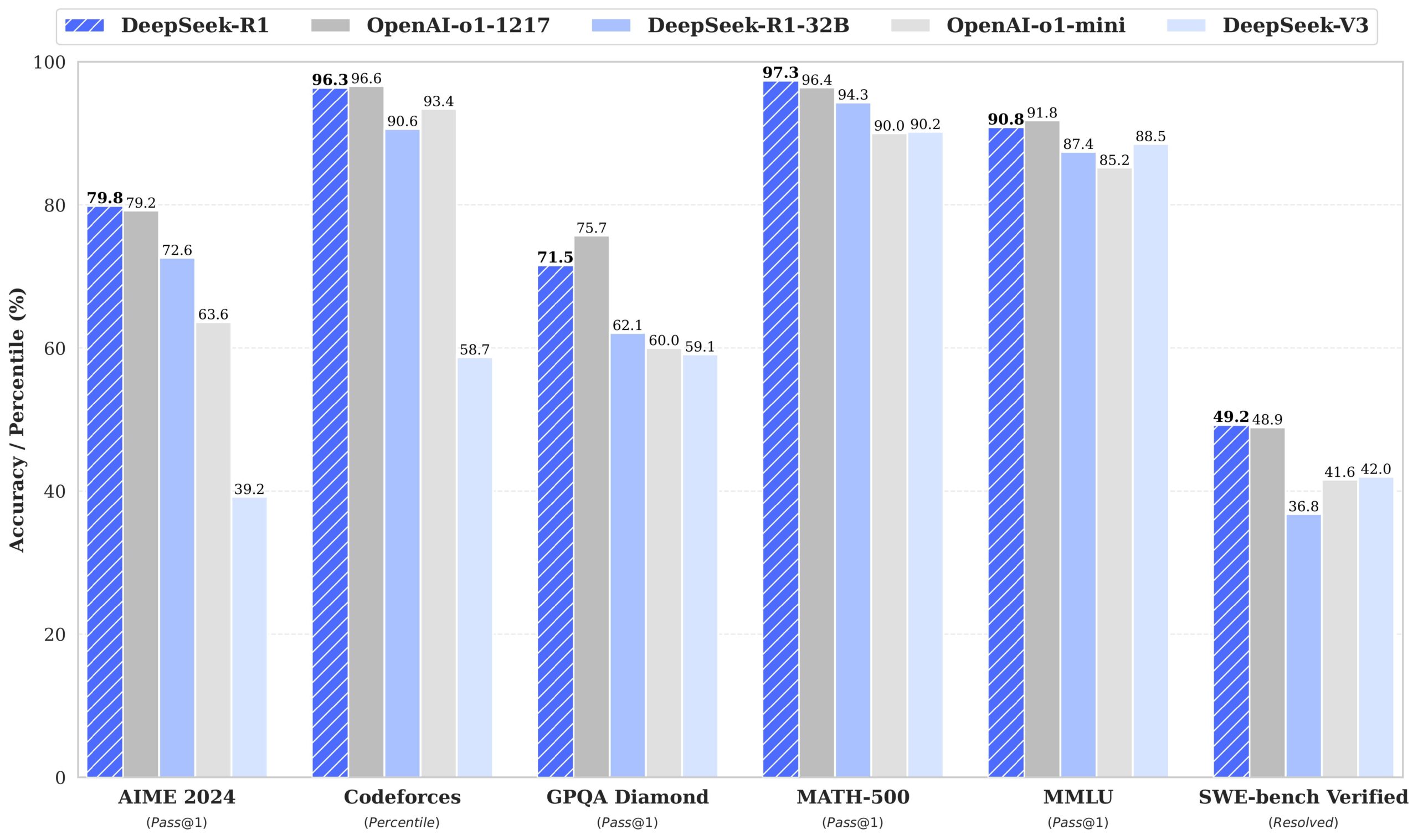
There’s a lot of technical stuff about how they managed to optimize AI training and get these extraordinary results. And they are extraordinary by the way. On many of these benchmarks the systems outperforms an awful lot of humans. For instance, in the American Invitational Mathematics Examination (AIME), OpenAI o1 and DeepSeek R1 solved around 80% of the problems, when the median score for high school math students was 33%. But that’s not the big news from the perspective we are looking at.
In terms of energy efficiency, DeepSeek’s approach has been estimated to be around 95% more efficient than traditional AI training methods. By optimizing its software and hardware utilization, the company significantly reduced the power needed for computation. Their training process, costing around $5.57 million, suggests a highly efficient use of both financial and energy resources compared to OpenAI’s estimates of over $100 million for similar performance benchmarks.
So much for hyperbolic projections of energy demands for data centers of large language models and most generative AI.
Further, sharp eyes will have spotted “we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models.” Yes, not only did they achieve absurd efficiency gains and absurd quality through their software optimization, they made it available to everybody, everywhere for free, including the exact techniques they used to achieve the efficiency gains.
That means that OpenAI, Microsoft, Google, Amazon, and everybody else’s training models can use the techniques themselves, and will. When OpenAI can save around $95 million with some coders’ time, you can be sure that they will do that.
One of the things that’s been amusing to me in the past year or two in the AI space are the people claiming that the USA is years ahead of China in the AI realm. The biggest gap I read was that they were five years behind. I found that amusing because being engaged in the space professionally part of every week, I know that 40% of papers in AI are from Chinese researchers, and that in the top 5% cited papers they are neck and neck with the USA. That is unusual, as in most STEM fields Chinese researchers are even more prevalent, so the USA hasn’t entirely lost the race that they are hoping to still win.
What the USA has is a lot of data centers. As of March 2024, the United States had about 5,388 data centers, which is more than any other country in the world. This represents about 45% of the world’s operational data centers. That’s right, that 4.4% of demand is partly because the USA has a lot more data centers than any other country, including China. US data centers operate software solutions that people around the world use, so it’s not that US consumers and business are computer hogs, it’s more like the USA is the data center for a lot of the world.
And electricity demand hasn’t been increasing in other segments of the US population. While GDP has tripled in the last 25 years, electricity demand has been flat. That’s despite lots more screens and lights everywhere, as the screens and lights are all energy sipping LEDs and now OLEDs. Data center use is like heat pumps and electric cars, another reason why the USA has to build a lot more renewables, storage, and transmission.
Will western AI giants use the DeepSeek models? Probably not, because the USA is swinging its big stick about all things China these days, and it’s just another concern for buyers who are already quite leery of AI in the solutions that they are buying. But the techniques are right there, and can be engineered into the giants’ models without any ‘Chinese content’ concerns.
It’s worth mentioning another proviso on this, that DeepSeek’s claims have not been duplicated by third parties. That they are open about their results and shared the models means that the benchmark performances will likely be verified shortly. Their claims about energy performance will take longer, but are also amenable to third-party validation, something that’s undoubtedly underway already.
The last proviso to keep in mind is that AI models are very much susceptible to Jevons Paradox, which states that improvements in the efficiency of resource use often lead to an overall increase in consumption of that resource, rather than a decrease, due to lower costs. That was based on observing coal plant efficiency in Jevons’ era, and can be observed by all the lights everywhere all the time in modern societies. And its why we keep occasionally finding the limits of the absurdly powerful hardware we have to run software on.
So this deflates the big AI electricity demand spike. It doesn’t eliminate it and it doesn’t mean that siting data centers and getting enough low-carbon electricity to them isn’t a concern. But it should put this entire concern about ChatGPT and the like in context, at least for energy demand, which is the point of this article. If you’d like to complain about equity and copyright and the like, fill your boots, but in comments on this piece, please stick to energy and carbon emissions concerns, not your perception of the ethics of AI on other issues. (Faint hope that anyone will follow this advice, but it’s worth a try.)
This is all quite obvious to people like me, by the way, and there are a lot of people like me, late stage career technologists who have seen it all before and have the scars. So why is everyone freaking about about AI electricity demand? Who benefits?
Well, the usual suspects benefit. If everyone is pointing at data centers, ChatGPT, and AI, they aren’t pointing at cars, planes, refineries, pipelines, and industries burning an awful lot of natural gas. While I haven’t seen it traced yet, I have no doubt that fossil fuel industry PR types are rubbing their hands at another opportunity to take the spotlight off the real problems and amplifying echo chambers among the easily distracted. Don’t be one of the easily distracted.
The real problem is that the west isn’t building renewables, storage, and transmission remotely quickly enough, and isn’t electrifying our economies remotely quickly enough. AI electricity demand is only a concern because we’ve been sleepwalking so far. It’s time to wake up.
Chip in a few dollars a month to help support independent cleantech coverage that helps to accelerate the cleantech revolution!
Have a tip for CleanTechnica? Want to advertise? Want to suggest a guest for our CleanTech Talk podcast? Contact us here.
Sign up for our daily newsletter for 15 new cleantech stories a day. Or sign up for our weekly one if daily is too frequent.
CleanTechnica uses affiliate links. See our policy here.
CleanTechnica’s Comment Policy